|
沒有Reference genome的物種 RNA_seq的應用:
(1) 可以快速了解全基因組尚未解碼的物種中, 會表達的基因種類與相對數量。可以在這些尚無Reference genome的物種中, 快速的發掘出基因轉錄體。對於日後要研究基因表現時, 可以方便設計出如real time RT-PCR primer、microarray或是in situ hybridization的探針。 (2) 若經過良好的de novo基因拼接後, 可以得到預期性的全長cDNA, 大大的降低全長基因選殖的困難度。 (3) 一般提供4-5Gb測序資料, 通常可以拼接與註解出大約30,000-50,000個unigenes。 |

|
|
有Reference genome的物種 RNA_seq的應用:
(1) 通常可以用來比較兩種或多種條件下, 具有差異性表現的基因種類為何。由於RNA_seq定序的深度較深, 能夠覆蓋的深度較一般常用的microarray為廣, 所以利用RNA-seq來找尋差異性表現基因逐漸變成是學術界的主流工具。 (2) 實際實驗上發現RNA_seq的解析力較microarray強大許多, 能夠篩選出更多具有差異性表現基因。也能夠避免因為microarray沒有布陣基因而造成的flase negative現象。 (3) 一般提供0.5Gb測序資料, 可以註解出大多數unigenes的表現。 |

|
力鈞NGS 轉錄組生資分務流程圖
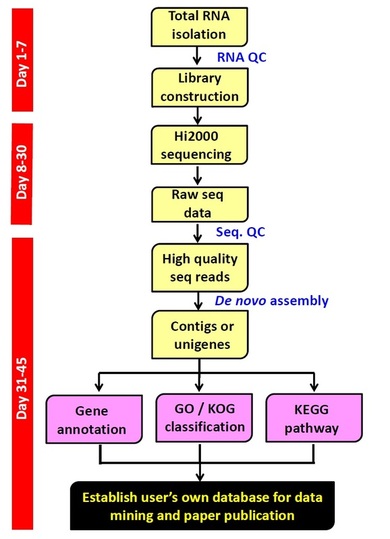
|
(1) Total RNA isolation:
力鈞公司會對客戶寄送的RNA樣本進行品質的QC, 若通過QC則會直接進行後續定序工作; 若QC失敗會主動通知客戶重新送件, 以避免客戶浪費寶貴的金錢與時間 (2) Library construction: 力鈞公司採用標準的方法構築library, 主要是方便進行後續pair end的定序工作 (3) Hiseq 2000/2500測序: 力鈞公司目前採用Hiseq2000進行NGS定序工作, 2013年中起將採用最新型Hiseq2500進行NGS定序工作, 用以加速進度, 減少客戶等待的時間 (4) Unigene assambly: 力鈞公司採用標準的方法(CLCbio+CAP3)進行contig assembly, 也接受客戶指定使用其他串接軟體 |
轉錄體的de novo assmebly與基因註解服務
力鈞生技公司的技術優勢可以提供客戶下列訊息:
(1) 任意物種的高通量分析
RNA-seq測序能夠研究與發掘任意物種中的轉錄本,無需任何預先的序列資訊。
(2) 高靈敏度
每個獨立的測序通道可以檢測多達5Gb的RNA分子讀序,為轉錄本的發現和研究提供了極大的資料深度與覆蓋率,能夠檢測表現豐度極低的稀有RNA轉錄本。
(3) 高品質資料與可信度
RNA測序具有極大的測序通量,靈敏度與準確性,無需重複實驗,同時其產生的定量資料與即時定量PCR結果具有高度的一致性。
(4) 加值型的生物資訊分析
力鈞生技公司尤其專精於RNA的測序與生物訊息註解,可以注釋RNA的資訊,分析其相對表達水準。能夠使用最新最完整的公用資料庫注釋原始資料中已知的RNA。
(5) 價錢合理的NGS測序服務
力鈞生技公司採用Illumina Hiseq2000/2500新型NGS測序儀,可以增加測序通量並解有效降低測序成本,保證提供同業中最合理的測序服務價格。
力鈞生物RNA-Seq服務樣品要求
樣品要求 Total RNA
1) 樣品純度:OD 260/280值應在1.9~2.2 之間,RNA 28S:18S≥1.5 推薦 RIN ≥8;DNA 應該去除乾淨。
2) 樣品濃度:最低濃度不低於100ng/µl。
3) 樣品總量:每個樣品總量不少於15µg。
4) 樣品溶劑:要溶解在H2O或TE (pH 8.0)中。
(1) 任意物種的高通量分析
RNA-seq測序能夠研究與發掘任意物種中的轉錄本,無需任何預先的序列資訊。
(2) 高靈敏度
每個獨立的測序通道可以檢測多達5Gb的RNA分子讀序,為轉錄本的發現和研究提供了極大的資料深度與覆蓋率,能夠檢測表現豐度極低的稀有RNA轉錄本。
(3) 高品質資料與可信度
RNA測序具有極大的測序通量,靈敏度與準確性,無需重複實驗,同時其產生的定量資料與即時定量PCR結果具有高度的一致性。
(4) 加值型的生物資訊分析
力鈞生技公司尤其專精於RNA的測序與生物訊息註解,可以注釋RNA的資訊,分析其相對表達水準。能夠使用最新最完整的公用資料庫注釋原始資料中已知的RNA。
(5) 價錢合理的NGS測序服務
力鈞生技公司採用Illumina Hiseq2000/2500新型NGS測序儀,可以增加測序通量並解有效降低測序成本,保證提供同業中最合理的測序服務價格。
力鈞生物RNA-Seq服務樣品要求
樣品要求 Total RNA
1) 樣品純度:OD 260/280值應在1.9~2.2 之間,RNA 28S:18S≥1.5 推薦 RIN ≥8;DNA 應該去除乾淨。
2) 樣品濃度:最低濃度不低於100ng/µl。
3) 樣品總量:每個樣品總量不少於15µg。
4) 樣品溶劑:要溶解在H2O或TE (pH 8.0)中。
NGS RNA Seq 轉錄組定序生資服務
|
差異基因GO富集柱狀圖
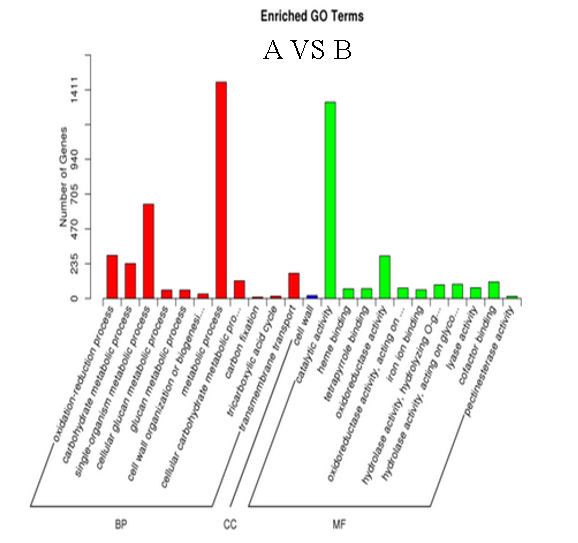
A 樣本和 B樣本的GO Terms 比較圖
|
差異基因卞氏圖表
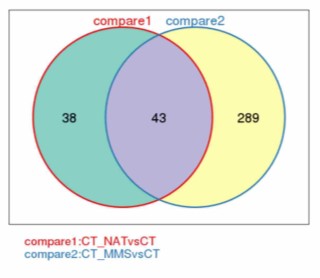
差異基因卞氏圖表兩個樣品差異基因的個數,以及共同差異基因的個數
|
不同實驗條件下基因表達水準比對圖

RPKM盒形圖,橫坐標為樣品名稱,縱坐標為log10(RPKM+1),每個區域的盒形圖對五個統計量(至上而下分別為最大值,上四分位數,中值,下四分位數和最小值)
|
差異基因火山圖

有顯著性差異表達的基因用紅色點表示;橫坐標代表基因在不同樣本中表達倍數變化;縱坐標代表基因表達量變化差異的統計學顯著性
|
|
定量飽和曲線檢查分佈圖
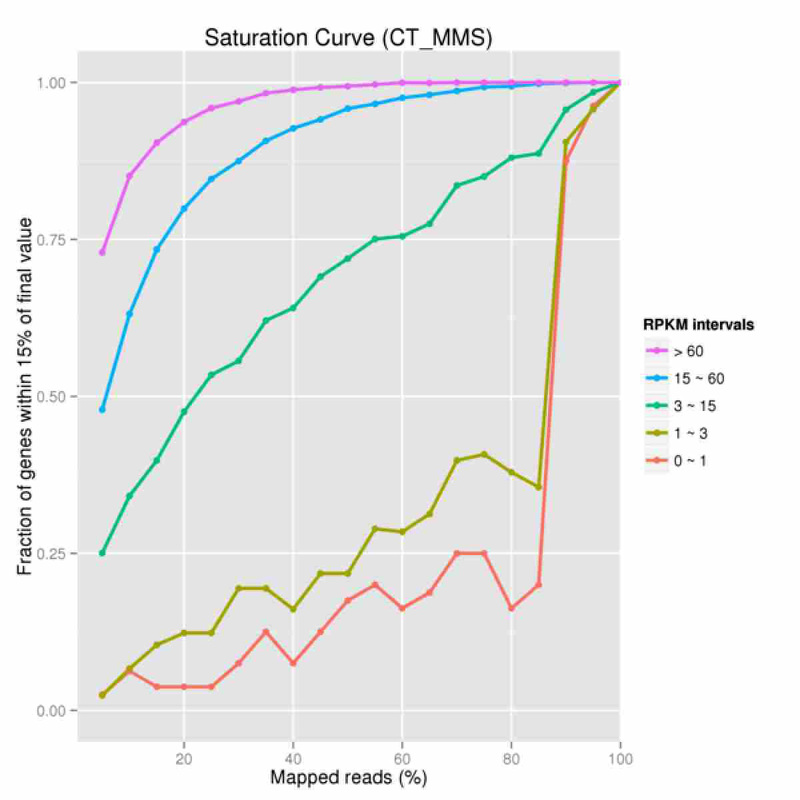
橫坐標代表定位到基因組上的reads數占總reads數的百分比,縱坐標代表定量誤差在15%以內的基因的比例
|
表達水準的飽和曲線的具體演算法:分別對10%、20%、30%……90%的總體定序資料單獨進行基因定量分析,並把所有資料條件下得到的基因的表達水準作為最終的數值。用每個百分比條件下求出的單個基因的RPKM數值和最後對應的基因表達水準值進行比較,如果差異小於15%,這個基因在這個條件下定量是準確的。
|
差異基因GO富集DAG圖
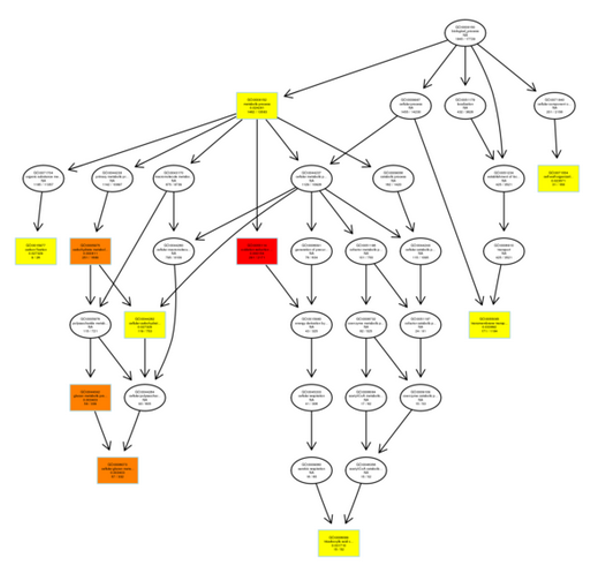
每個節點代表一個GO,方框代表的是富集程度為TOP10的GO,顏色的深淺代表富集程度,顏色越深就表示富集程度越高,每個節點上展示了該TERM的名稱及富集分析的p-value
|
有向無環圖(Directed Acyclic Graph,DAG)為差異基因GO富集分析結果的圖形化展示方式,分支代表包含關系,從上至下所定義的功能範圍越來越小,一般選取GO富集分析的結果前10位作為有向無環圖的主節點,並通過包含關係,將相關聯的GO Term一起展示,顏色的深淺代表富集程度。項目中分別繪製生物過程(biologicalprocess)、分子功能(molecular function)和細胞組分(cellular
component)的DAG圖。
|
|
差異基因聚類圖
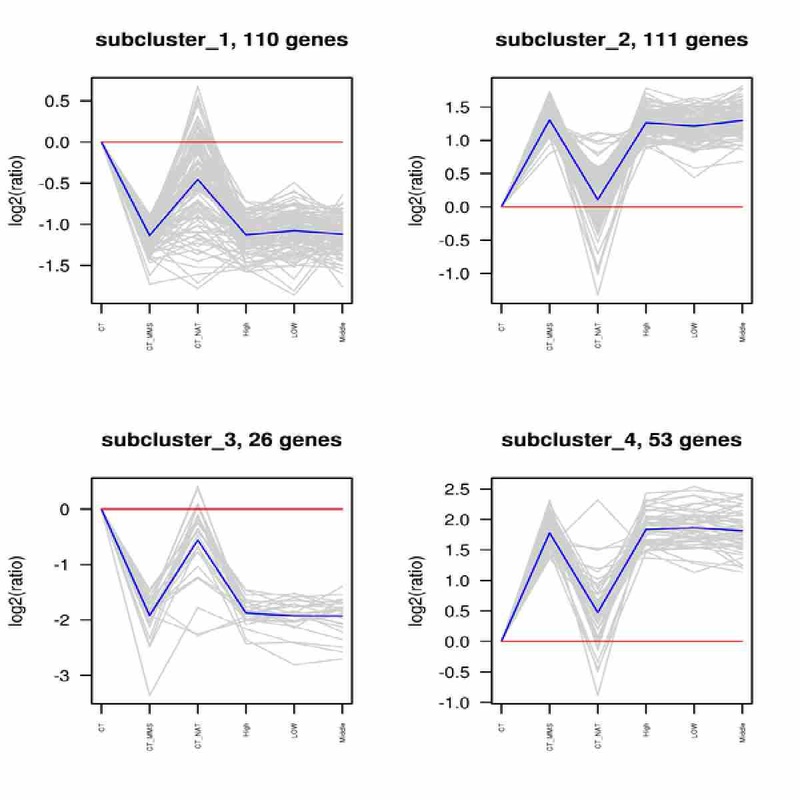
|
log2(ratios)折線圖,灰色線條表示一個cluster中的基因在不同實驗條件下相對表達量的折線圖,藍色線條表示這個cluster中的所有基因在不同實驗條件下相對表達量的平均值的折線圖,x軸表示實驗條件,y軸表示相對表達量
|
rpkm層次聚類圖
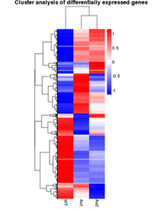
|
整體rpkm層次聚類圖,以log10(RPKM+1)值進行聚類,紅色表示高表達基因,藍色表示低表達基因。顏色從紅到藍,表示log10(RPKM+1)從大到小
|
|
差異基因KEGG富集散點圖
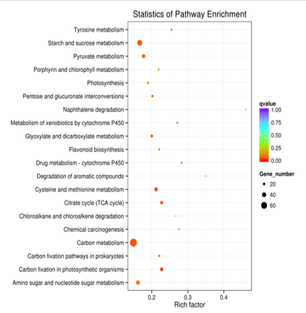
|
縱軸表示pathway名稱,橫軸表示Rich factor,點的大小表示此pathway中差異表達基因個數多少,而點的顏色對應於不同的Qvalue範圍
|
差異基因富集出的通路圖
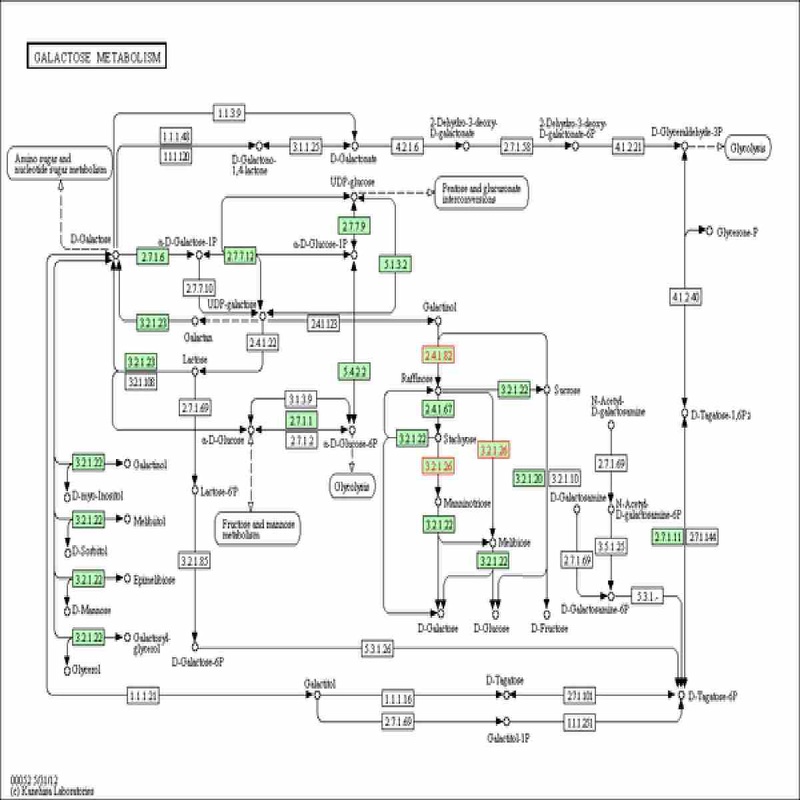
|
差異基因富集出的通路圖展示出來,上調基因的KO節點標紅色,包含下調基因的KO節點標綠色,包含上下調的標黃色。滑鼠停於標記的KO節點,會彈出差異基因細節框,標色同上,括弧中數字為log2(Foldchange)。以上可離線操作,如連接網路,點擊各個節點,可直連結到KEGG官方資料庫中各個KO的詳細資訊
|



